隨著數據規模的爆炸式增長,大數據系統的數據采集與處理存儲支持已成為現代企業數字化轉型的核心。數據采集產品作為大數據系統的入口,其架構設計與數據處理存儲服務的高效協同直接影響整體系統的性能與可靠性。本文將從數據采集產品架構的組成要素出發,并深入探討其與數據處理和存儲支持服務的集成機制。
一、數據采集產品的架構分析
數據采集產品通常采用分層架構設計,以支持高并發、低延遲和可擴展的數據接入。其核心組件包括:
- 數據源適配層:負責對接多樣化數據源,如日志文件、數據庫、物聯網設備、API接口等,通過連接器或代理程序實現數據抽取。
- 數據傳輸層:采用消息隊列(如Kafka、RabbitMQ)或流處理引擎(如Flink、Spark Streaming)進行數據緩沖與實時流轉,確保數據不丟失且有序傳輸。
- 數據預處理層:在數據進入存儲前進行清洗、過濾、格式轉換和輕量聚合,以降低后續處理負載。
- 控制與管理層:提供配置管理、監控告警、調度協調等功能,保障采集流程的可運維性。
典型架構示例中,分布式部署是主流趨勢。例如,采用微服務架構將各層模塊解耦,結合容器化技術實現彈性伸縮,并通過統一元數據管理維護數據血緣關系。
二、數據處理與存儲支持服務的關鍵作用
數據處理和存儲服務為采集到的數據提供價值挖掘與持久化能力,其核心支撐體現在:
- 數據處理流水線:通過批處理(如MapReduce、Spark)與流處理(如Storm、Flink)引擎,實現數據的實時分析與離線計算。例如,流處理可對采集的傳感器數據進行即時異常檢測,而批處理支持歷史數據的深度聚合分析。
- 分布式存儲體系:采用多級存儲策略,包括:
- 熱數據存儲:使用內存數據庫(如Redis)或列式存儲(如HBase)支持低延遲查詢。
- 溫數據存儲:依托分布式文件系統(如HDFS)或對象存儲(如S3)平衡性能與成本。
- 冷數據存儲:通過歸檔至低成本介質(如磁帶庫)實現長期留存。
- 數據治理與安全:集成元數據管理、數據質量監控與加密訪問控制,確保數據在生命周期內的合規性與一致性。
三、架構協同優化實踐
在實際系統中,數據采集產品需與處理存儲服務深度耦合。例如:
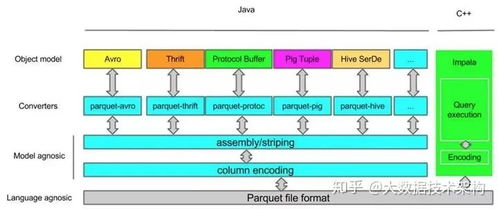
- 通過Schema-on-Read技術(如Parquet格式),采集層可直接將數據寫入存儲系統,由處理層按需解析,提升靈活性。
- 利用存儲計算分離架構,采集數據持久化至云原生存儲(如Delta Lake),處理服務按負載動態調配資源,實現成本優化。
- 引入數據湖倉一體模式,統一采集入口,支持原始數據直接入湖(Data Lake),并經ETL管道轉換后入倉(Data Warehouse),滿足多場景分析需求。
大數據采集產品的架構演進正朝著智能化、云原生與實時化方向發展。其與數據處理存儲服務的無縫集成,不僅提升了數據流轉效率,更通過彈性擴展與智能治理,為業務創新提供了堅實基礎。未來,隨著邊緣計算與AI技術的融合,采集與處理存儲的邊界將進一步模糊,形成更敏捷的數據驅動體系。